使用Beautifulsoup和requests爬虫豆瓣电影
只用30行代码
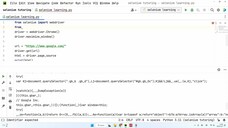
代码如下:
import requests
from bs4 import BeautifulSoup
import pandas as pd
hrefs, titles, actors, ratings, quotes = [[] for i in range(5)]
result = [hrefs, titles, actors, ratings, quotes]
for page in range(0, 250, 25):
url = f"https://movie.douban.com/top250?start={page}&filter="
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
" AppleWebKit/537.36 (KHTML, like Gecko)"
" Chrome/108.0.0.0 Safari/537.36"}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, "lxml")
infos = soup.find_all("div", class_="info")
print("*"*50)
for index, info in enumerate(infos, start=1):
print(index+page)
href = info.find("a")["href"]
title = info.find("a").get_text().replace("\n", "").replace(" ", "")
actor = info.find("p").get_text().replace("\n", "").replace(" ", "")
rating = info.find("span", class_="rating_num").get_text()
if info.find("span", class_="inq") is None:
quote = "nothing"
else:
quote = info.find("span", class_="inq").get_text()
one_result = [href, title, actor, rating, quote]
for i in one_result:
print(i)
for i in range(5):
result[i].append(one_result[i])
column_name = ["href", "title", "actor", "rating", "quote"]
df = pd.DataFrame({column_name[i]: result[i] for i in range(5)})
df.to_csv("douban.csv")

 Feedback
Feedback Report
Report Feedback
Feedback






![[Mantis VS Scorpion] Who'd Win, Agile Assassin Or Heavy Warrior?](https://pic.bstarstatic.com/ugc/2850c61ae01fb6413068a4921d1b5b04ee50367a.jpg@320w_180h_1e_1c_90q.webp)

![[Insect] Mantis VS Centipede | Epic Battle, Precise And Elegant](https://pic.bstarstatic.com/ugc/aa341851f324e9ca54902b449c78673c263eb652.jpg@320w_180h_1e_1c_90q.webp)
![[Unboxing] A Snake which Is Worthy of a Chanel](https://pic.bstarstatic.com/ugc/849754861a1900d701aaf3b7c5e5ac48cd098e9b.jpg@320w_180h_1e_1c_90q.webp)



![[Animals]Open three eggs of Goliathus](https://pic.bstarstatic.com/ugc/78f6c3fdc56fb00dba13c829f0f46b8b4f63ea84.jpg@320w_180h_1e_1c_90q.webp)





















![[Reptile pets] The horned frog eats a spider](https://pic.bstarstatic.com/ugc/94fc222b4bd676e307922ae59eeff77bb50c72e8.jpg@320w_180h_1e_1c_90q.webp)

